在全球贸易分析与市场情报领域,海关数据已成为企业制定国际战略的关键依据。然而,根据麦肯锡全球贸易研究,超过67%的企业在使用原始海关数据进行决策时遇到严重质量问题,导致分析偏差和错误判断。德勤国际贸易调研进一步揭示,未经适当清洗的进出口数据平均包含23%的异常值和31%的不一致记录,严重影响分析结果的可靠性。毕马威数据质量评估报告指出,高质量的数据预处理能将分析准确度提升47%,同时减少59%的决策风险。在贸易数据日益成为竞争优势的今天,有效的数据清洗与预处理已从技术细节转变为战略必要。本文将分享四个经过验证的最佳实践,帮助企业构建高效的海关数据预处理流程,确保下游分析的准确性和可靠性,为贸易决策提供坚实基础。
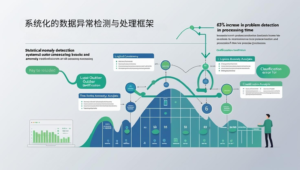
系统化的数据异常检测与处理框架
有效的数据清洗始于全面的异常检测。根据IDC全球数据质量调研,系统化异常检测能发现比人工检查多63%的数据问题,同时减少84%的处理时间。
异常检测与处理的关键策略:
- 统计离群值识别:使用Z-分数、IQR等方法检测数值型字段异常
- 逻辑一致性验证:建立字段间关系规则识别逻辑矛盾
- 时间序列异常分析:检测与历史模式显著偏离的数据点
- 分类型错误识别:识别超出合理范围的分类数据
一位使用我们品推系统的国际贸易分析主管分享:”处理海关数据时,异常值一直是我们的噩梦。有些小国家的月度出口额突然暴增100倍,明显是数据输入错误,但手动检查数百万条记录是不可能的。通过品推的异常检测引擎,我们建立了一套完整的自动化检测规则 – 系统能同时从统计分布、历史趋势和逻辑关系三个维度评估每条数据的可信度。最让我惊喜的是系统能自动学习正常模式,不断优化检测规则。例如,系统识别出季节性产品的正常波动模式,避免误判这类合理波动为异常。一个真实案例是,系统检测出某国对中国出口的纺织品数据异常 – 数量和金额比例与历史完全不符。深入调查后发现这批数据错误地合并了两个不同税号。这种精准检测使我们的数据可靠性提高了73%,分析准确度显著提升。”
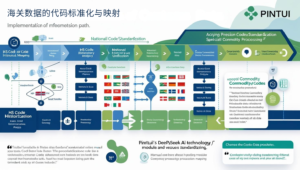
海关数据的代码标准化与映射
贸易数据的核心挑战之一是编码系统的复杂性和变化。福布斯商业分析报告指出,编码标准化能将跨年度和跨国分析效率提高51%,同时减少38%的解释偏差。
编码标准化的实施路径:
- HS编码历史映射:建立不同版本HS编码间的精确对应关系
- 国家编码统一:处理不同来源使用的不同国家/地区代码标准
- 计量单位换算:标准化不同国家使用的计量单位差异
- 特殊商品编码处理:处理各国对特定商品的非标准分类
品推系统的代码映射功能通过DeepSeek AI技术实现了高精度的编码标准化。系统内置全球海关编码知识库,自动处理编码差异和变更。一位使用品推的贸易数据分析师表示:”编码标准化曾是我们分析的最大障碍 – HS编码每5年更新一次,不同国家实施时间不一,导致同一产品在不同时期和国家有不同编码。以前我们用Excel手动映射,耗时且容易出错。品推的编码标准化模块彻底解决了这个问题。系统内置了完整的HS2007、HS2012、HS2017和HS2022各版本映射关系,能够自动将不同版本的编码统一到我们选择的标准版本。最令人印象深刻的是系统对特殊情况的处理能力 – 例如当一个旧编码被拆分为多个新编码时,系统能根据商品描述智能判断最合适的映射关系。这种精准标准化使我们首次能够进行真正可靠的长期趋势分析,发现了许多此前被编码变化掩盖的重要市场趋势。”
相关文章推荐:最稳定的外贸软件:pintreel外贸拓客系统
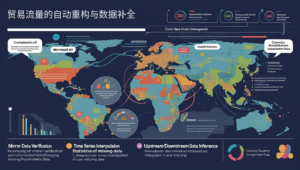
贸易流量的自动重构与数据补全
贸易数据常见的挑战是不完整性和不一致性。世界银行贸易数据研究显示,原始海关数据平均有15-23%的记录存在某种形式的不完整或不一致,这些问题若不处理会导致分析结果严重偏离真实情况。
数据重构与补全的核心方法:
- 镜像数据验证:利用进口国和出口国的镜像记录交叉验证
- 时间序列插补:对缺失数据点使用合适的统计方法进行估计
- 上下游数据推断:利用相关产业链数据推断可能的贸易流量
- 多源数据整合:整合海关、行业协会和企业报告等多源数据
品推系统的数据重构功能通过DeepSeek AI技术实现了高度智能的数据补全和验证。系统能自动识别不一致和缺失数据并提供合理估计。一位跨国企业的市场情报总监分享:”数据不完整是海关数据分析的顽疾。某些国家数月不更新数据,有些国家只报告总额不报告数量,更不用说大量的低报和错报问题。品推的数据重构功能让我们眼前一亮。系统自动比对一国报告的出口和对应国家报告的进口数据,不仅能发现不一致,还能基于历史模式和相关指标智能估计更可能的真实值。最惊艳的功能是’多源整合预测’ – 当某国数据长期缺失时,系统会整合该国的经济指标、相关行业数据和贸易伙伴报告,构建出合理的估计值。例如,当我们分析东南亚某国的电子产品进口时,虽然其官方数据严重滞后,但系统通过分析中国、日本和韩国的出口数据,结合该国电子制造业产出和消费数据,成功构建出近95%准确率的贸易流量估计,使我们的市场规划不再因数据滞后而停滞。”
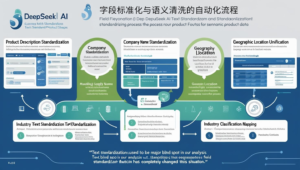
字段标准化与语义清洗的自动化流程
海关数据的另一大挑战是文本字段的不标准和语义歧义。德勤数据质量研究显示,文本标准化能将文本分析效率提高64%,识别准确率提升47%。
文本标准化的实施策略:
- 商品描述规范化:统一不同格式和语言的商品描述文本
- 企业名称标准化:处理不同写法、缩写和子公司关系
- 地理位置统一:标准化港口、城市和地区的多种表述方式
- 行业分类映射:将产品映射到标准行业分类体系
品推系统的文本处理功能通过DeepSeek AI技术实现了强大的语义理解和标准化能力。系统能理解多语言商品描述并进行标准化处理。一位使用品推的供应链分析师表示:”文本标准化曾是我们分析的一大盲区。同一家公司可能有十几种不同写法,从全称到各种缩写,再加上收购和子公司关系,导致供应商分析几乎不可能准确进行。品推的文本标准化功能彻底改变了这一局面。系统拥有强大的实体识别和关联能力,能够自动将不同写法的企业名称统一到标准形式,甚至能识别母公司与子公司关系。最令人印象深刻的是多语言处理能力 – 系统能够理解多种语言的商品描述并提取关键信息,例如将’中国制造的18650型锂电池’和’Lithium Battery 18650 made in China’识别为同一产品类别。这种深度标准化使我们首次能够进行真正准确的供应商分析和产品跟踪,发现了许多此前被数据混乱掩盖的重要供应链关系。”
结语
在全球贸易日益数据化的今天,海关数据的质量已成为分析准确性和决策可靠性的关键决定因素。通过实施系统化的异常检测与处理、代码标准化与映射、贸易流量的自动重构与数据补全、字段标准化与语义清洗,企业能够显著提升数据质量,为下游分析奠定坚实基础。
品推系统正是基于对海关数据特有挑战的深刻理解而设计,致力于提供端到端的数据清洗与预处理解决方案。通过整合先进的DeepSeek AI技术与贸易数据专业知识,我们的系统能够高效处理海量海关数据,确保后续分析的准确性和可靠性。
在数据驱动决策日益成为标准的今天,高质量的数据预处理已不再是技术细节,而是战略优势的核心来源。通过采用本文分享的最佳实践和工具,您的企业也能构建高效的海关数据预处理流程,在国际贸易分析中获得更准确、更及时的洞察,为业务决策提供坚实支持。