为什么“重复数据”是海关数据最大隐患?
许多外贸团队在使用海关数据时,经常遇到这些痛点:
-
同一个客户被识别多次,结果多人跟进、撞单冲突
-
数据导入CRM系统后冗余字段爆炸,难以识别主线索
-
批量发信时重复命中,退信率、垃圾标记率上升
-
AI推荐系统误判相似客户为多个目标,影响潜力评分与推荐精度
本质上,数据不“干净”,一切智能化都是低效甚至反效果的。
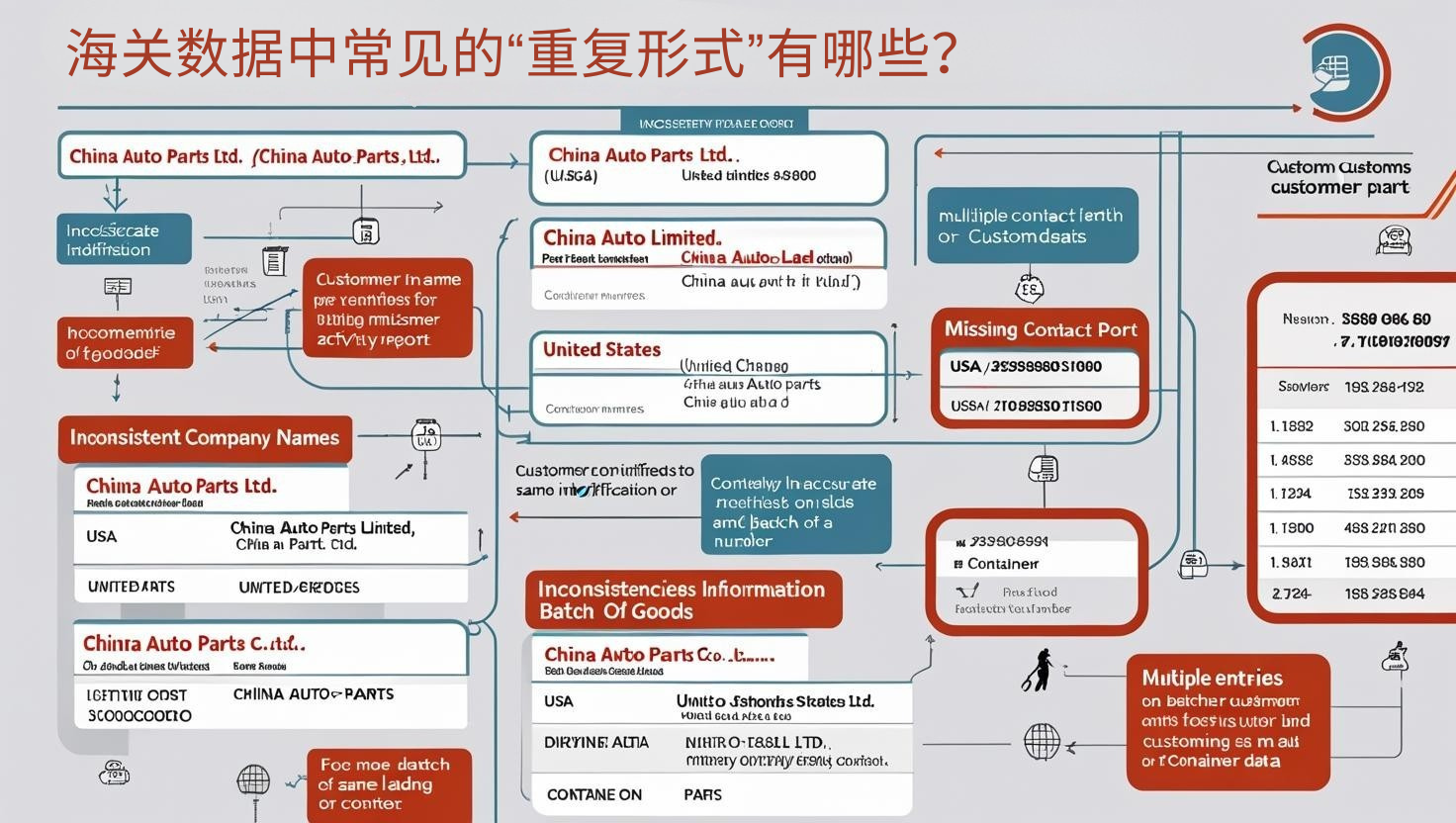
海关数据中常见的“重复形式”有哪些?
1. 公司名大小写或拼写差异
-
China Auto Parts Ltd.
-
CHINA AUTO PARTS LIMITED
-
China Auto-Parts Co., Ltd.
→ 实为同一客户,系统却识别为三条记录。
2. 地址或国家字段重复
-
同一客户出现在“USA”与“United States”字段下
-
省略/包含港口信息导致识别失败
3. 联系人或邮箱缺失导致无法合并
-
多条记录都无联系人,仅凭公司名难以合并
-
info@xxx.com 被多个销售同时开发,误判为不同客户
4. 多次进口同一批次货物被分条计入
-
一次采购被切分为不同提单或柜号
-
导致系统记录重复采购行为,判断为“高活跃客户”
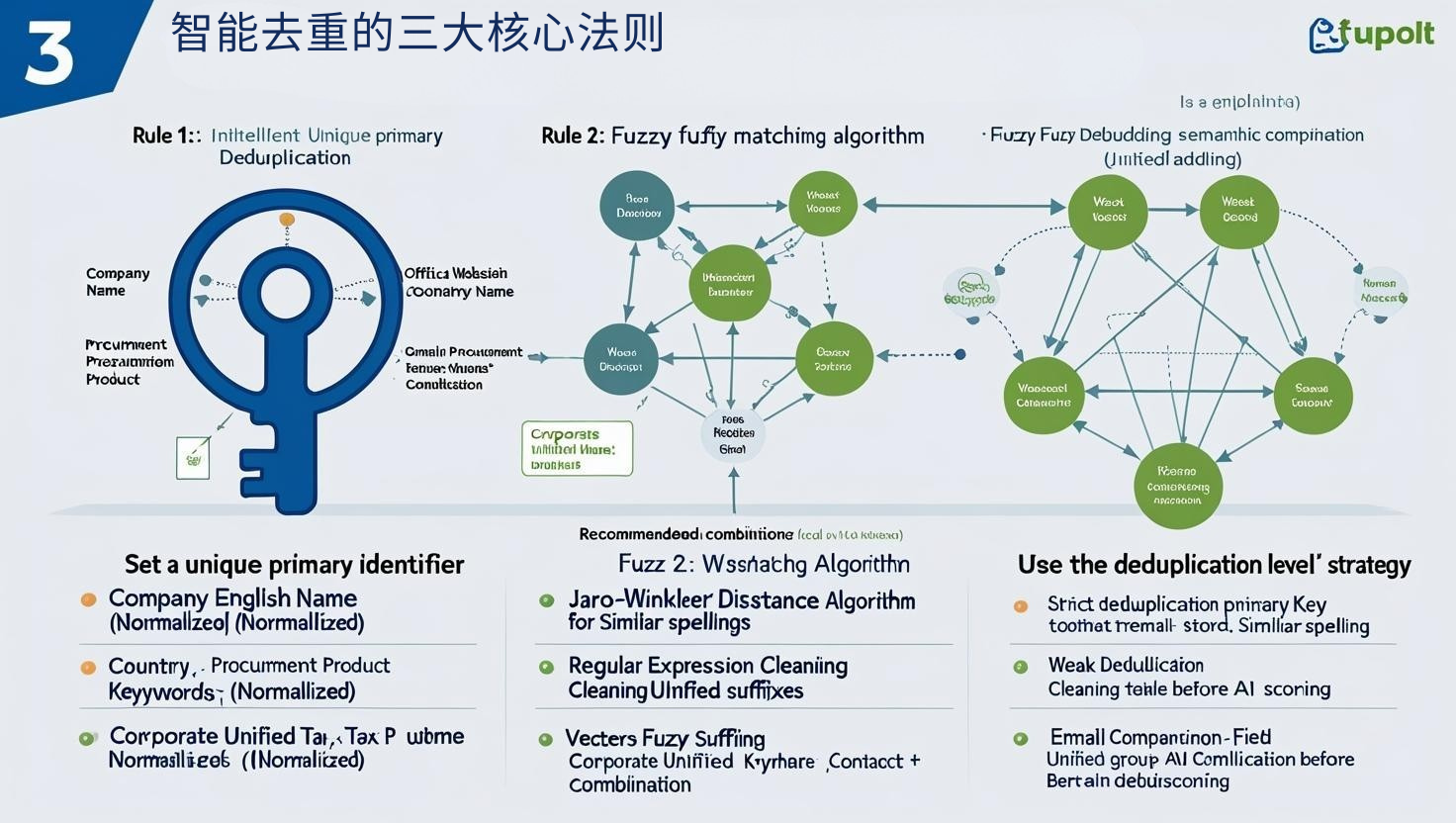
智能去重的三大核心法则
法则一:设定唯一识别主键(Primary Identifier)
推荐组合字段作为去重主键:
如需更高准确率可引入:
-
邮箱 / 官网域名
-
企业统一税号(如有)
-
联系人 + 电话组合
越多高置信度字段参与交叉验证,去重越精准。
法则二:模糊匹配算法 > 简单完全匹配
传统的“完全匹配”去重逻辑只识别字面一致,但无法识别拼写变形与缩写。
推荐使用以下方法增强智能性:
-
Jaro-Winkler / Levenshtein 距离算法:识别相似拼写公司名
-
正则表达式清洗:统一公司后缀(如Ltd. / Limited / Co., Ltd.)
-
向量化模糊比对(如BERT Embedding):高级工具可做语义去重
法则三:使用“去重级别”策略分层清理
并非所有重复都必须强行合并,应分层管理:
| 去重级别 | 策略 | 应用场景 |
|---|---|---|
| 严格去重 | 完全重复、主键一致 | CRM入库、AI评分前清洗 |
| 弱去重 | 拼写相似、归一字段一致 | 邮件群发、团队开发前统一 |
| 留存重复 | 产品类别不同、时间间隔大 | 复购客户分析、历史行为建模 |
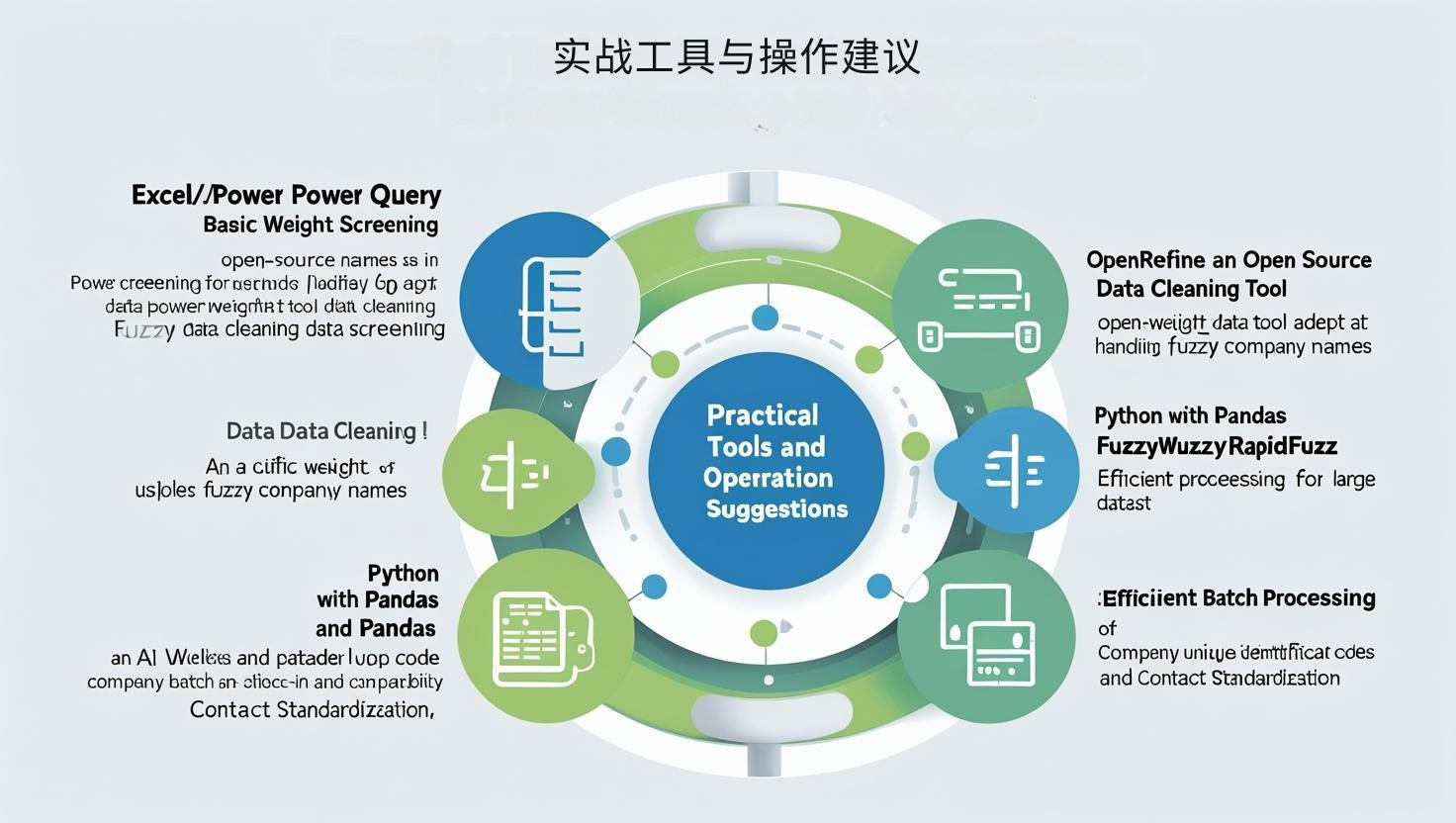
实战工具与操作建议
工具推荐:
-
Excel / Power Query:基础筛重
-
OpenRefine:开源数据清洗神器(可处理模糊公司名)
-
Python + pandas + fuzzywuzzy / RapidFuzz:可批量处理大型数据集
-
AI线索平台(如SaleAI):内置公司唯一识别码(CID)+联系人标准化能力

去重后的数据,怎么用才最值?
✅ 精准发信:每个客户只被一个销售负责,避免重复打扰
✅ 精准推荐:AI可以更准确地判断客户行为与转化潜力
✅ 精准标签:可对唯一客户构建完整采购路径画像
✅ 精准跟进:数据少而精,销售节奏更聚焦
相关文章推荐:外贸开发神器:8大免费海关数据网站强烈推荐!
总结:数据不干净,一切增长都是“自我内耗”
在外贸数字化转型的道路上:
-
数据清洗 ≠ 技术问题,而是商业效率问题
-
重复记录 ≠ 信息更多,而是信息混乱
只有去重,才能让真正有价值的客户“浮出水面”。
