AltaVista. Lycos. 雅虎。曾经,这些是世界上最受欢迎的搜索引擎。然后谷歌出现了。它做出了更好的搜索。
自2002年左右以来,谷歌一直是搜索引擎的霸主,其统治地位每年都在增强。根据StatCounter,截至2月份,谷歌在全球搜索市场份额中占据了91.6%的份额。在过去的20年中,许多“谷歌杀手”已经出现并消失。
十年前,谷歌的前CEO兼执行主席埃里克·施密特(Eric Schmidt)表示,
OpenAI的ChatGPT可能会成为这种意想不到的变革吗?
我们为什么关心。OpenAI的CEO山姆·阿尔特曼似乎认为,将LLMs和搜索整合起来会很“酷”,从根本上改变人们搜索和思考的方式。诚然,谷歌仍然处于极为强大的地位,并且正计划推出类似的搜索生成体验。
以下是阿尔特曼在本周与莱克斯·弗里德曼(Lex Fridman)的一次采访中对谷歌、搜索、LLMs等的看法。
更好的方式。 阿尔特曼首先基本上称当前的谷歌搜索体验为“无聊”。他不想复制谷歌的模式,似乎他想重新发明搜索(具体来说:人们获取信息的方式),就像我们已经知道了20多年的那样:
“……如果问题是我们是否能够构建比谷歌或其他搜索引擎更好的搜索引擎,那么当然,我们应该去做,人们应该使用更好的产品,但我认为这样做会大大低估了这个可能。谷歌向你展示10个蓝色链接,嗯,还有13个广告,然后是10个蓝色链接,这是一种获取信息的方式。但让我感到兴奋的事情不是我们可以构建一个更好的谷歌搜索的复制品,而是也许有一种更好的方式来帮助人们查找、行动和综合信息。实际上,我认为ChatGPT对某些用例来说就是这样,希望我们能让它对更多的用例都变得如此。”
“但我认为说“我们如何做得比谷歌更好地给你提供10个排名的网页来查看”并不那么有趣。也许真正有趣的是去说,“我们如何帮助你获得你需要的答案或信息?我们如何在某些情况下帮助创造它,在其他情况下帮助综合它,或者在其他情况下指引你去找到它?”但很多人都试图只是做一个比谷歌更好的搜索引擎,这是一个艰难的技术问题,是一个艰难的品牌问题,是一个艰难的生态系统问题。我不认为世界需要另一个谷歌的复制品。”
再次回想施密特之前分享的引用——没有人会通过模仿谷歌搜索来认真挑战或击败谷歌。问问微软吧(抱歉,必应)。
Duane Forrester Yext的行业洞察副总裁,认为我们正在目睹传统搜索模式的重大转变:
“为什么要在搜索上与谷歌竞争?为什么不简单地提供无广告的搜索。你已经支付了使用ChatGPT的订阅费,所以包含无广告的搜索。简单地改变这种范式是削弱整个范式的简单方法。”
LLMs + 搜索。 什么会更酷?根据阿尔特曼的说法,将ChatGPT与搜索整合起来。
正如阿尔特曼在采访中所说:
“……我们对如何做到这一点感兴趣。那将是一个很酷的事情。”
“我认为没有人已经完全掌握了这个问题。我很愿意去做到这一点。我认为那将很酷。”
有传言称
ChatGPT正在开发一个网络搜索产品。正如我当时所说的,我对ChatGPT能否在传统搜索方面与谷歌竞争持怀疑态度,但阿尔特曼在这次采访中谈到的并不是谷歌的新版本。这是一种不同的东西。
OpenAI不想做谷歌所做的事情。但显然,阿尔特曼认为OpenAI目前还没有达到可以将LLMs + 搜索提升到足够高水平的地步,但他显然表达了对实现这一目标的兴趣。
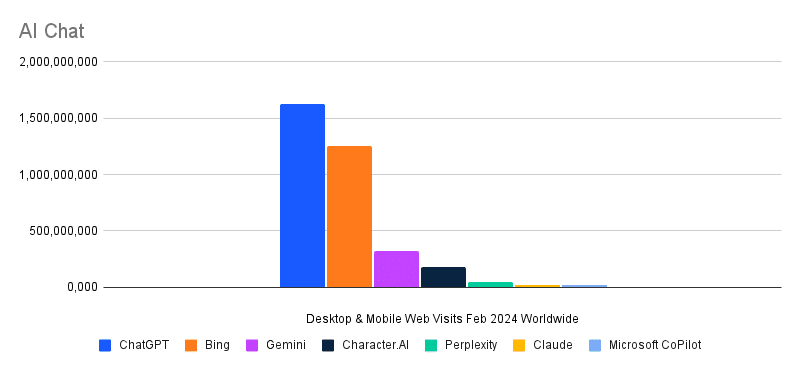
<p作为一个旁注,根据<rel=”noopener” target=”_blank”>SimilarWeb的数据,ChatGPT在2月份达到了新的美国访问量高峰——16亿次访问。
阿尔特曼讨厌广告。曾经,谷歌因其简洁的广告体验而备受喜爱。显然,根据阿尔特曼的说法,情况已经不再如此:
“我从审美的角度不太喜欢广告。出于许多原因,广告在互联网上是必要的,以推动其发展,但这只是一个短暂的产业。现在的世界更加丰富。我喜欢人们为使用ChatGPT而付费,并知道他们得到的答案不受广告商的影响。我相信有一种广告形式适合LLMs,并且我相信有一种以公正方式参与交易流的方式,但也很容易想象到未来的反乌托邦愿景,你问ChatGPT某事,它会说,“哦,你应该考虑购买这个产品”,或者,“你应该考虑去这里度假”,或者其他什么。”
“我不知道,我们有一个非常简单的商业模式,我很喜欢它,我知道我不是产品。我知道我在支付,这就是商业模式的运作方式。当我使用Twitter或Facebook或谷歌或其他任何其他伟大的产品,但是支持广告的伟大产品时,我并不喜欢,我认为在AI的世界里,情况不会变得更好,而是变得更糟。”
阿尔特曼表示,他相信OpenAI有一个可以支付其计算需求的出色业务模式,而不必求助于广告:
“……感觉应该有更多的广告进步,不会干扰内容的消费,也不会在很大程度上干扰,就像你说的那样,它会操纵真相以迎合广告商。”
但是。这一切目前都是假设。正如<rel=”noopener” target=”_blank”>Brett Tabke,Pubcon的CEO所指出的,谷歌仍然在OpenAI面前拥有一个重大优势——那就是其数据宝库:</rel=”noopener”>
“以图书为例。据估计,谷歌已经数字化了大约4000万本书——这是一个用于训练大型语言模型的不可思议的资源,而OpenAI没有像那样规模的任何资源。”
“然后是地图。随着我们深入研究视觉语言模型,谷歌数十亿的街景照片是一个金矿。当然,OpenAI可以获取卫星图像,就像谷歌一样,但谷歌的收藏是真正特别的,其他人似乎没有。”
“YouTube:在训练新的视频AI模型时,谷歌拥有所有的牌。”
“Android:谷歌对手机使用了解一切。”
“Chrome:像点击数据一样,他们肯定在搜索中使用这些数据。这也一定会让他们在观察ChatGPT的大规模参与数字时感到恐慌。”
“Gmail:他们对电子邮件使用、电子邮件趋势、电子邮件内容、电子邮件一切都了如指掌。必定有大量可用于训练AI模型的可操作数据。”